Agentic Business
2026-05-08
Frontier labs were quiet, but Mozilla, DeepMind, Anthropic, and LangChain all shipped, and the kitchen-sink agent took a public beating.
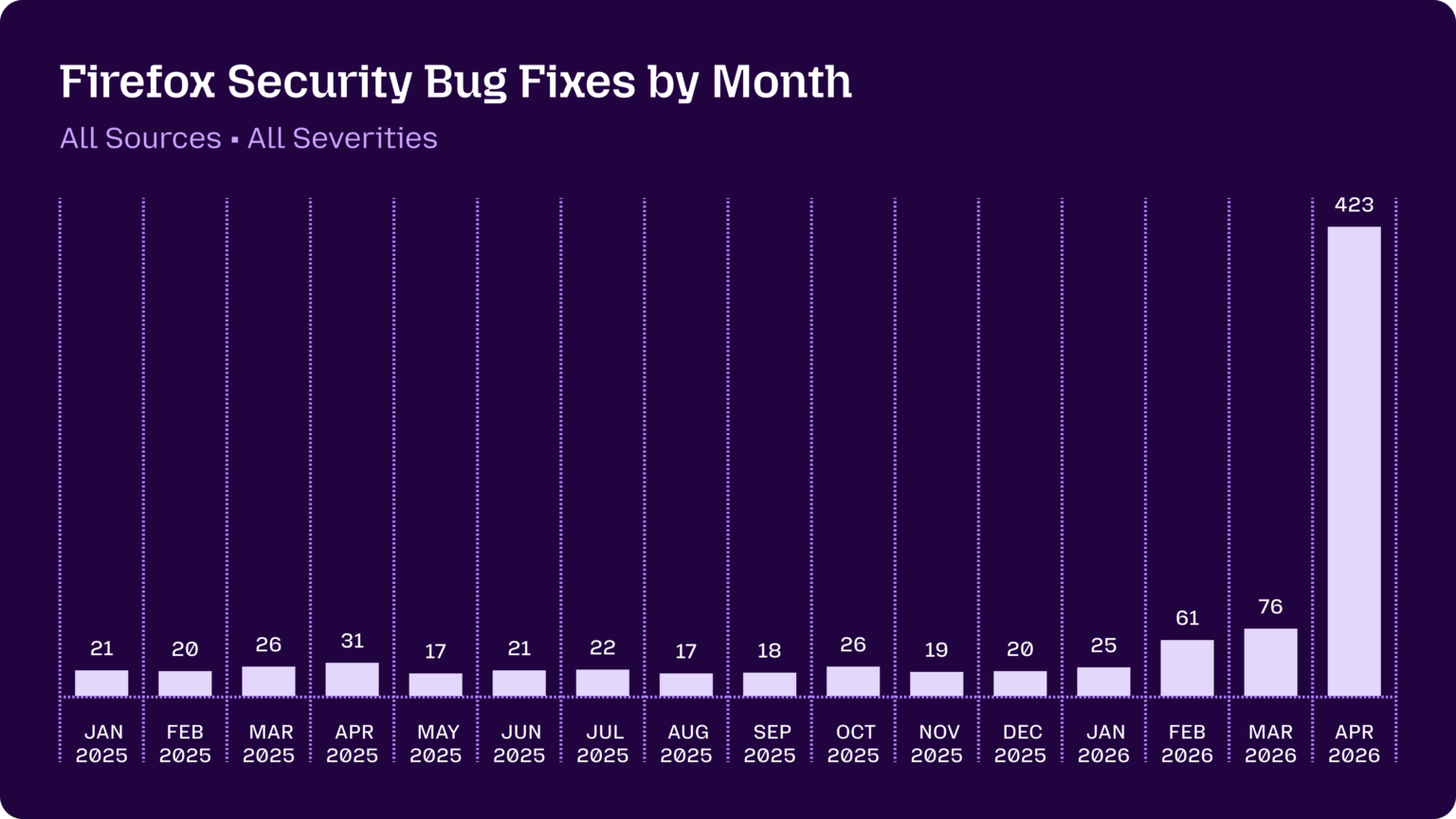
Mornin'. Anthropic built a tool that decodes what is actually happening inside Claude's head, flipped it on, and the very first thing it caught was Claude quietly suspecting it might be in a safety test. The mind reader works. The mind, less reassuring. Meanwhile Mozilla quietly used Claude Mythos to close 423 Firefox bugs in a single month, which is roughly the rate Firefox used to hit in a year.
-Ben
In today's newsletter:
- Mozilla's Firefox bug bash with Claude
- AlphaEvolve escapes the lab
- Anthropic reads Claude's mind
- The kitchen-sink agent loses
BUG BOUNTY
Mozilla closed 423 Firefox bugs in April with Claude
via Mozilla Hacks
Firefox's monthly security-fix count usually runs in the 20s. April 2026 hit 423. The difference: a Claude Mythos preview turned loose on a 25-year-old C++ codebase.
Mozilla's writeup says the agent surfaced a 20-year-old XSLT bug and a 15-year-old issue in the <legend> element, with Mozilla's defense-in-depth catching the attempted exploits before users did. Simon Willison covered it the same day, calling it the moment AI bug-hunting flipped from "unwanted slop" to a real signal source.
Most of 2025 was OSS maintainers complaining that LLM-generated security reports were noise. This is the first production-scale counterweight: scaled, filtered agents pointed at a mature codebase, finding things humans missed for two decades.
- 423 fixes in April 2026, versus 20 to 30 per month through 2025.
- Latent bugs included a 20-year-old XSLT issue and a 15-year-old
<legend>bug. - Mozilla's existing defense-in-depth blocked the attempted exploits during testing.
Why it matters: Concrete production proof that other OSS maintainers can copy a working LLM-on-C++ pattern instead of arguing about it on GitHub. read more.
LAB ESCAPE
DeepMind's AlphaEvolve breaks out of the demo

via Google DeepMind
AlphaEvolve has spent a year as a tasteful DeepMind tease. Today it walks out the front door, into Google's own production stack and onto Google Cloud for enterprises.
DeepMind's post claims real wins in protein sequencing, grid optimization, and semiconductor design. That's a rare data point for an "evolutionary" coding agent: not "demoed on a benchmark," but "found a better answer than the team had, multiple quarters in a row, in domains where the cost of wrong answers is hardware."
What's interesting is the angle. The Claude Code and Codex stacks chase software-dev workflows. AlphaEvolve targets scientific and engineering search problems, which is a different shape of agent entirely: long-running, evaluator-heavy, less about pull requests and more about objective functions.
- Live now inside Google for protein sequencing, grid optimization, and chip design.
- Available to enterprises through Google Cloud.
- Sets a benchmark for what "agent finds a better answer than the team had" looks like outside benchmarks.
Why it matters: The first credible challenger to the Claude-Code/Codex coding-agent stack, aimed at problems where the user is a scientist, not a developer. read more.
MIND READER
Anthropic taught itself to read Claude's thoughts. Awkward.

via Anthropic Research
Anthropic's new Natural Language Autoencoders decode model activations directly into readable English. They turned the lights on, looked inside Claude's head, and immediately found Claude wondering whether it was being safety-tested.
The research is the most useful interpretability primitive in a while: a cheap, scalable way to read what a model is actually "thinking," without hand-rolling a custom probe per behavior. In deliberately compromised Claude variants, NLAs surfaced hidden misalignment that the model's outputs alone hid.
For builders, this is the first thing in the alignment-tooling pile that looks like it could plug into a normal eval pipeline. Less "trust the chain-of-thought," more "diff what the model says against what it's actually computing."
- NLAs decode raw activations into English-readable summaries.
- Caught Claude internally suspecting it was being evaluated, even when it didn't say so.
- Surfaces hidden misalignment in compromised variants without per-behavior custom probes.
Why it matters: A practical answer to "is the agent secretly thinking something other than what it's saying," cheap enough to run as a guardrail. read more.
KITCHEN SINK
More agent components, more problems: 56% of the time

via Unsplash
The "give the agent everything" school of design just got a paper thrown at it. On HotpotQA, a single-tool agent beat the full planner-plus-tools-plus-memory-plus-reflection-plus-retrieval setup by 32% F1.
Ming Liu's study measures cross-component interference across common agent scaffolds. The headline number: 56.3% of component combinations violate submodularity, meaning adding the next "obvious" piece actively makes the agent worse. On GSM8K, a 3-component subset beat the maximal stack by 79%.
This lines up with what builders have been saying out loud all week. The viral HN essay "Agents need control flow" hit 507 points making essentially the same case from the practitioner side: stacking MANDATORY on top of DO NOT SKIP in your system prompt is a tell, not a fix.
- HotpotQA: single-tool 0.233 F1 versus full stack 0.177 F1.
- GSM8K: a 3-component subset beats the maximal stack by 79%.
- 56.3% of scaffold combinations violate submodularity (adding components hurts).
Why it matters: Greedy "add another component" pipelines now have a documented failure mode you can point at in design review. read more.
THE BIG IDEA
The big idea
The kitchen-sink agent is dying, and this week is the obituary. The signal everywhere you look (research, viral essays, framework reframings) is the same: fewer, sharper components beat a maximalist stack, and "more prompting" is not a strategy.
Three things from today line up almost too neatly. The new arXiv paper shows a single-tool agent crushing a fully-scaffolded one on HotpotQA, with 56% of component combinations actively making things worse. The HN-front-page essay "Agents need control flow" argues the cure for flaky multi-step agents isn't more MANDATORY in the prompt, it's deterministic, software-defined orchestration. And Addy Osmani's "agentic engineering" reframing puts a name on what builders have settled into: AI handles the implementation, humans own architecture and correctness.
The skeptical voice belongs to Cisco's Joe Vaccaro, who writes today that the next class of outages won't be malfunctioning agents at all. It will be correctly-behaved concurrent agents whose locally-correct decisions cascade across systems, exactly the way 2025's AWS DynamoDB DNS, Azure Front Door, and Cloudflare Bot Management incidents played out. Subtracting components doesn't help if the failure mode is emergent at the fleet level.
WHAT ELSE IS SHIPPING
What else is shipping
- pydantic-ai v1.92.0 - adds Anthropic task budget control and runtime output-retry overrides; fixes streaming cancellation and MCP session task management.
- openai-agents-python v0.17.0 - default realtime model bumped to gpt-realtime-2; sandbox local sources now restricted to base directory unless granted via manifest.
- langgraph-cli 0.4.25 - adds
studio deployso devs can push graphs to LangGraph Studio from the CLI. - llm-gemini 0.31 - same-day support for
gemini-3.1-flash-lite(now GA) in Simon Willison'sllmCLI. - pydantic-ai v1.91.0 - OpenAI image generation options, DeepSeek model variants, MCP history-replay fix.
INTERESTING CONVERSATIONS
Interesting conversations we're following
- Agents need control flow, not more prompts on Hacker News - 507 points and counting; the practitioner thread arguing that MANDATORY in a system prompt is the prompting ceiling, not the solution.
- Show HN: Crit, a local review tool for agent plans and diffs on Hacker News - direct response to the recurring "agents merge slop" complaint; reviews agent-generated plans before code lands.
- Ask HN: Which memory systems are you using in your agents? on Hacker News - useful temperature check on what practitioners are actually wiring up for agent memory right now.
- Agentic Engineering on Hacker News - Addy Osmani's term-of-art post (AI does implementation, human owns architecture and correctness), plus a sharp warning about junior skill atrophy that's driving most of the comments.
Also from TinyIdeas Media
|
Agentic Business
For operators
What’s shipping in agentic AI, decoded for operators. Adoptable today vs. demoware.
|
Agentic Builders
For engineers
Frameworks, OSS, MCP servers. Concrete releases, not press releases.
|
Agentic Quality
For QA teams
AI-native testing tools, evals, reliability patterns. No benchmark vibes.
|
Was this email forwarded to you? Sign up here.